Has this ever happened to you?
You go to write a formula, and you type in the name of the block you need, but there are multiple options. For example, maybe you need the Salary metric for existing employees, but you can’t tell from the list which metric labeled “Salary” is for existing employees and which one is TBH (to be hired).
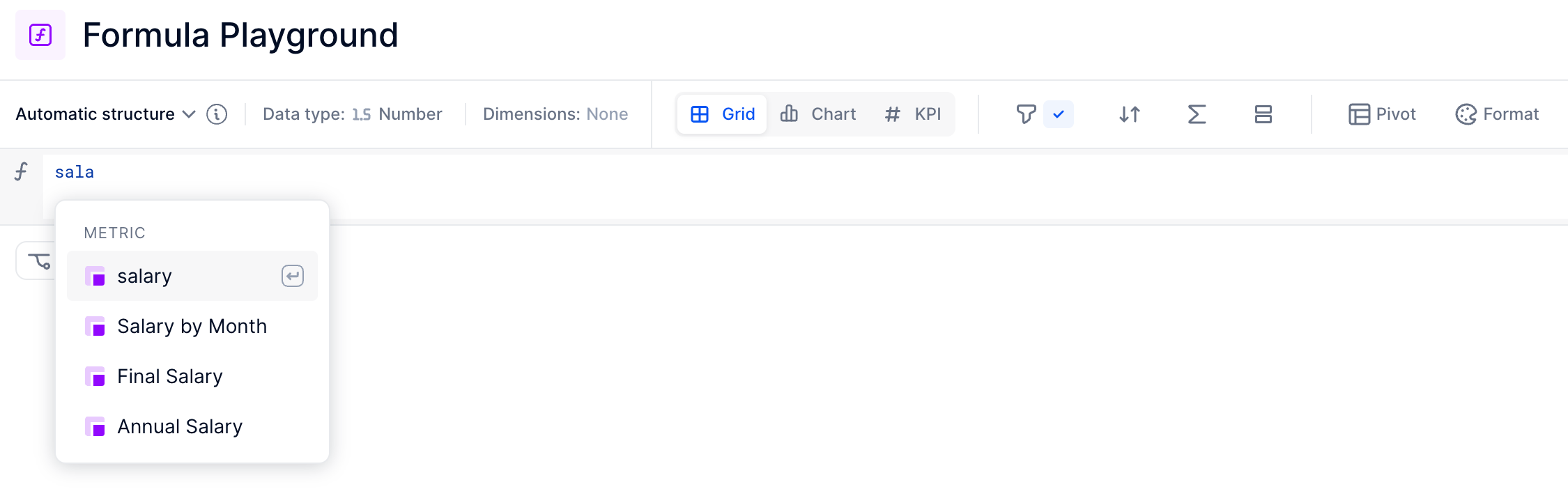
Understandably, choosing the wrong metric in this instance could create huge errors now, or further down the dependency tree if left unchecked. But when you’re in the middle of modelling, it can be hard to double check or take extra time.
This is why naming conventions in your Pigment workspace are so important.
At every level, naming conventions will help you improve clarity and functionality for everyone using your workspace. In this article, we’ll show you how we implement naming conventions in our templates and in customer workspaces at the application, folder, block, board and view level.
TLDR but still need the info? Skip to the bottom for the basic principles in handy bullet-point style.
Why names are important in Pigment
Because Pigment will automatically order items in an ascending alphanumeric order (i.e. 0-9 followed by A-Z) with special characters (like brackets and underscores) coming first, how you name your items has a huge impact on how easy it is to navigate the workspace and your applications, find what you are looking for and understand the logic behind. This is true both for referencing blocks in formulas, like in the above example, but also for following defined processes and logic flows across multiple blocks or applications.
This can also help to document your model more clearly, helping you to visualise the way different blocks interact with one another. This can help new users, both modelers and end users, onboard more quickly. Finally, having a naming convention that aligns with our best practices makes it easier to collaborate with Pigment support and our SA team should you need it.
Defining and documenting your naming conventions
Before we get into the specifics of naming different types of items, it’s important to caveat that a naming convention is only as useful as it is memorable and intuitive for you and your team. A best practice won’t work if it doesn’t make sense for the way you think and model, or if you don’t stick to it rigorously and consistently.
Second, it’s important to document your naming system so that new and existing users can easily learn it. We recommend creating a board called “Application Guide” in each application, which would explain the purpose of each app, any eventual workflow or actions to be completed, the naming conventions, and any helpful definitions.
How we name applications
Application naming convention is quite simple and usually revolves around the goal of arranging your applications in the desired order within your workspace. Usually, we order applications as follows:
-
Hub : will contain your shared dimensions, calendar, exchange rate, security administration and any general settings used in more than one application in the workspace.
-
Use case-specific applications (for example: 02. Core Reporting, 03. Workforce Planning, 04. Opex Planning, 05. Topline Planning, etc.…)
Naming the Hub
We usually recommend having the Hub as the first application displayed on the workspace (top-left). That way it will be easier to access the Hub from another application when using the drop-down on the sidebar.
Organising your other applications
To effectively organise applications, we use two-digit numbers, e.g. 01. Hub. We also try to make the titles as descriptive as possible, meaning we would always choose “03. Workforce Planning” over “03. Headcount Planning” or “03. HC”.
And finally, if we are building an application that won’t be regularly used but needs to stay in the workspace, we would usually assign a prefix like “ZZ_” to relegate the app to the end of the display order. (We do, however, recommend regularly cleaning your workspace by deleting any unused or unneeded applications).
We also use suffixes occasionally, especially if we are duplicating an application to use for a test or for training. We usually do this just by adding the purpose to the end of the title, e.g. “03 Topline Planning - Training”. Once this application has served its purpose, it should be immediately deleted.
For more insights on how to organise your workspace through multi application architecture you can read this article
How we name folders
Folder naming conventions, similar to those for naming applications, are partially to help you order things within your workspace and make it easy to identify what will be inside without having to necessarily open it.
However, unlike applications, you’re likely to have dozens of folders or more, which adds a notable constraint to naming strategies. Simply put, when you add a new application, it’s not a big deal to rename your existing ones to create the desired order. But when you’re naming folders, you want to do so with enough flexibility that you won’t have to rename the existing ones as you add new ones.
The way we address this is to name folders in 10s rather than 1s. So for example, instead of naming our folders 2.1, 2.2, 2.3, etc., we advance by 10 so that new folders can be added in between. Here’s an example of what that might look like in practice as you build out your folders:
| | As you can see, the most you would ever need to rename to create the desired order would be those in the 10 range you’re working within.
For example, we usually use 0X for the basic folders we include in almost every application (click here to learn more about those), 1X for data loads and checks, and 2X onward for use case-specific blocks.
If you have a high volume of folders, you can add a layer of numbers using a period, e.g. 10.10, 01.11, 01.20,10.21, etc. This will allow you the same flexibility both before and after the full stop. |

In the example, you can clearly see what kinds of blocks you will find within the folder, and they’re arranged in an intuitive order according to the process and model structure. The same is true for boards, making it easier for your users to find what they need based on the action they wish to perform or the data they wish to find.
How we name blocks
So far, the naming conventions for different types of items have been very similar (and, spoiler alert, boards will be largely the same). However, for blocks, it’s important to be more nuanced in your naming to avoid confusion.
When we are creating a block in Pigment, the first thing to do is to name it. Our goal is to give a simple, explicit name that will give as many indications as possible on the purpose or role of the block we are creating in the application. We can also provide insights on the origin of the data or specific business processes involved by adding prefixes or suffixes to the name.
Of course, it’s impractical (and actually impossible) to answer all of those questions with a simple name, unless you created a code so complex you would need a cipher to read it.
So instead, we take a practical approach to block naming by starting with a list of defined prefixes, while still being open to the possibility of new ones as business processes and use cases demand it. These prefixes can also be used as suffixes or even combined together (example: “Asm_Input_Churn rate (%)” → this metric is used to input the churn rate assumption) – just make sure you’re consistent with the way you combine them, and that the ordering makes sense for your team and your use case.
A note on dimensions: these need to be named simply and concisely, as they’re displayed as-is in the whole model, including in your boards. This means we’re unlikely to use numbers or prefixes unless it’s clearer for the modeler and end user.
Here are the prefixes we most frequently use:
| Name | Description |
|---|---|
| Set | Blocks used for settings in the application |
| Map | Mapping metrics that are used in the application |
| Pull | Metrics using data from another application in the workspace but needed in this application. An acronym of the source application can be added (example: “Pull_WF_Headcount” → “WF” stands for “Workforce Planning”). |
| Push | Metrics shared with another application in the workspace. An acronym of the source application can be added (see example above). |
| Load | Metrics or Transaction Lists used to import manually or automatically data from an external source. The name of the source system can also be added (example: “Load_Employee_HRIS” → “HRIS” being the name of your HRIS). |
| Input | Metrics or transaction Lists used by an end-user to manually input data like assumptions or requests used in the model calculations. |
| Calc | Metrics that are running some calculations based on other blocks (usually used to identify intermediary metrics from final ones containing end results). |
| Res | Metrics that are containing final results that can be used elsewhere in the application or in the workspace. |
| Asm | Metrics used for assumptions (usually combined with the “Input” prefix). |
| ARM | Metrics used to configure access rights (can be divided into “ARM_Input” and “ARM_Res”). Adding “Write” and/or “Read” as a suffix can indicate if the metric is used to restrict read and or write access rights. |
| BPM | Metric used to configure board permissions (can be divided into “BPM_Input” and “BPM_Res”). |
| Lock | Metrics used to apply restrictions on “write” access rights to lock and prevent changes (example: “Lock_Version by Year”). |
| Rep | Metrics created for reporting purposes only. These metrics are not used in the application other than displayed in a board (for example to display a specific KPI like “Last Headcount”). |
| Exp | Metrics or Tables used to export data from Pigment to be used elsewhere. |
| Tbl | Used for Tables. Facilitate the creation of boards using tables by being able to filter using this prefix. Can add “[ ]” to reorder the table as the first object to appear within a folder. |
| Ctrl | Metric created to run some controls on the data quality used in the application. |
Of course, you should add your own prefixes to this list depending the specificities of your application. And depending on your use case, you will need block types specific to that as well. Here are some of the use case-specific prefixes we often use:
| Name | Description |
|---|---|
| EE | Blocks containing Existing Employees data |
| TBH | Blocks containing To Be Hired data (from Head of department requests) |
| SC | Blocks used to calculate the Sales capacity |
| REV | Blocks used to calculate the Revenue |
Again, this is not a comprehensive list, and you should change or add to it in whatever way makes the most sense for the application you’re working within.
More advice on Block naming
If there is a specific order to the calculation that needs to be kept to understand the flow, add a number to the name, e.g. MCM_01_Input. Use _99_ for the result metrics so that, if intermediate steps are added, you don’t need to rename the result metric.
Using “(#) and “($)” or any other symbol or abbreviation can be helpful to provide more information about the metric use/purpose and the type of data it holds
When creating metrics to test calculations of changes, always use a “-TEST” suffix to enable quick filtering of all test metrics. They should ideally not stay as-is in the model, and should either replace old metrics (which can be kept with an “-OLD” suffix) or should be deleted.
Here is an example of a block name:
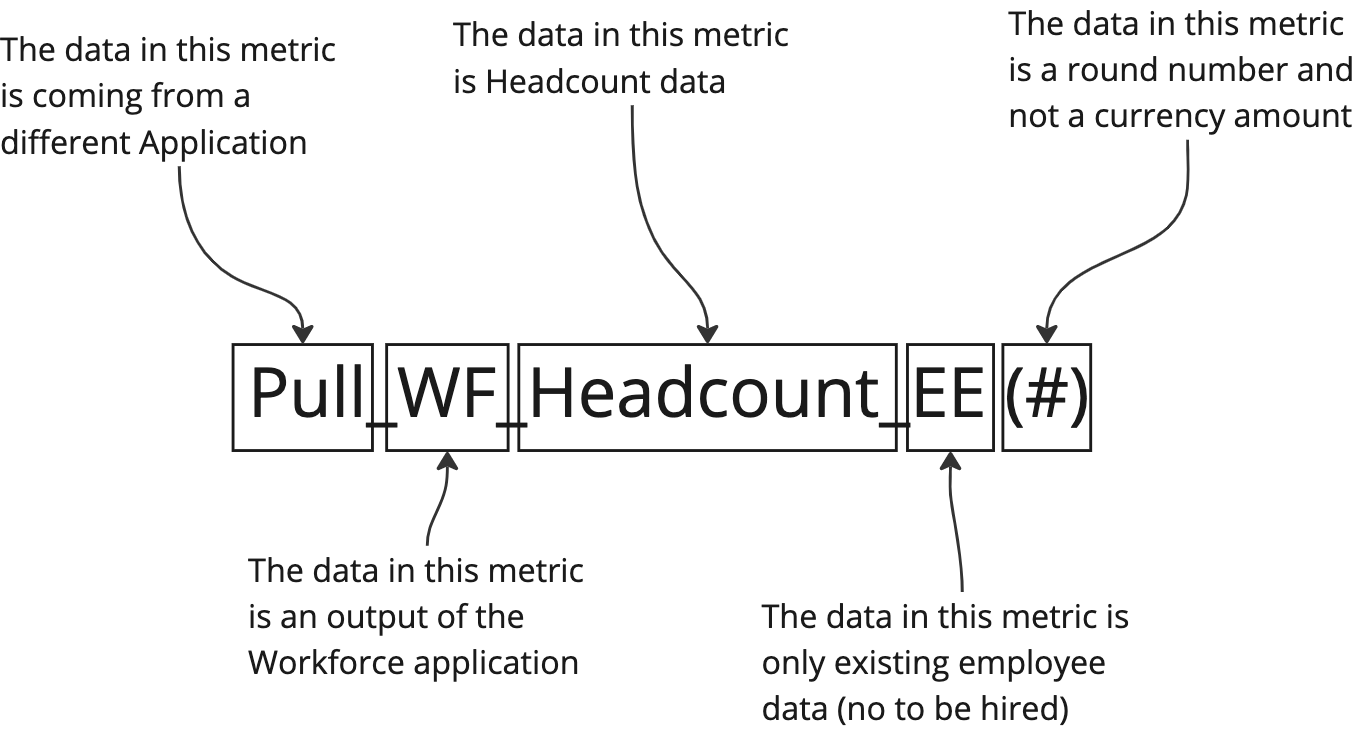
As you can see from this example, all we have to do is read the name of the metric to gain valuable insights into its role and purpose and how it should be used in the model.
You can change the ordering of the prefixes/suffixes if you prefer a different logic; what’s important is to keep a consistent, logical approach to naming at the level of complexity that is most appropriate for your model.
Here are more examples of block names:
-
Push_PR_New Business Revenue ($): metric with new business revenue data that is shared from the Revenue application to be used in a different application
-
Set_Map_Month to Ramp-up Month: Mapping metric located in the “00. Settings” folder that is used to translate Ramp-up Month back to the Month dimension
-
Load_EE_Employee Data_HRIS: Transaction list used to load the existing employee data from an external HRIS system
-
Asm_Input_Merit Tenure: assumption metric used to input the minimum tenure for the Merit increase
-
SC_Asm_Sales Quota_Input ($): Sales Capacity metric used to input assumption on Sales Quota
-
Customer_Existing_Forecast (#): metric with the number of existing customer forecast
-
Lock_Actuals_Write: metric used to apply “write” Access Rights restriction to prevent end-user from changing the Actuals data
-
Check_Pipeline_Region missing: metric created to run a check on the transaction list and identify the number of rows without the “Region” information
-
Arm_Cost Center x County_Read: metric used to apply “read” Access Rights restriction to allow end-user to see data only in specific Cost Center and/or Country
-
Rep_EBITDA & Revenue Forecast: metric created only to be able to display a particular information on a board
-
Exp_Tbl_Cost Center billing (€): Table used to export data for billing purposes
Remember that you can also use square brackets in your block naming conventions to make the blocks appear at the top of the folder, but again, this should serve to enhance the understanding of the block’s contents and its role in the process and model.
A quick note on referencing blocks:
When referencing blocks in Pigment, typing an empty space indicates two separate objects. If you type the name without the space, the platform will surface metrics with a space as well. We don’t recommend using periods (.) or colons (:) in your block names because it will break the referencing.
Unlike an Application or Folder that can’t be referenced, we do NOT recommend you start your block name with a number, because Pigment will consider it as if it’s a number, not a block name, which will end up in breaking the referencing too. This limitation can be overcome by using the single quote ‘ ‘ before starting to type any number but it might not be the first thing you think of doing when referencing a block.
How we name boards
Similarly to folders and applications, naming boards is all about clarity and prioritisation within the view. Your end users are likely to be navigating across boards, so it should be clear what will be found in the board, and they should be arranged in a way that makes sense for the business process. This means using two-digit numbers to order your boards, and choosing full labels over acronyms or abbreviations.
Here is an example of best practice board naming:

How we name views
When naming views of blocks, numbering is less important than clear labelling, including the target user and the purpose of the view. We will also use “KPI” or “Graph” or “Chart” prefixes to make navigation easier when configuring block views in a board. Sometimes it can be helpful to specify the role or persona that will be using the view for this block as a prefix (example: “Department Head_Requests to validate”).
Conclusion
Naming conventions are important for both navigability and accuracy in Pigment. By choosing a naming convention that works for your team, you can create a consistent way to arrange and reference your key items (applications, folders, blocks, views). We’ve offered our best practices as a guide, but the best choice will always be what works best for your team.
Naming conventions in a nutshell:
Create a naming convention that suits your needs based on or inspired by the one we present in this article. Make sure to write it down on a board in each application and keep it up to date.
Applications: Prefix with a 2-digit number for easy ordering – e.g. 03 Workforce Planning. Put the Hub first (00 Hub) and the rest in any logical order that makes sense for the use-cases applications.
Folders: Use 2-digit numbers, increasing by 10 for added flexibility – e.g. 10, 20, 30 – so you can add in new ones without renaming the rest.
Blocks:
For dimensions, keep the names concise yet descriptive, as these appear as-is throughout the application
For other block types, use a combination of prefixes and suffixes to name them, in an order that feels intuitive for you and enhances understanding of their purpose
Don’t use colons or periods in your block names to not break the referencing
When referencing a block with a space in the name, type it without the space or Pigment will think you’re referencing 2 separate objects
Boards: same as folders, with a focus on clarity of what’s inside and ordering based on process for the benefit of end users
Views: numbering is less important than clarity of labelling based on the target user and the purpose of the view
Ultimately, use whatever works best for your team and what will be used CONSISTENTLY!